今日は散布図のプロットを用いて、図の細かい所の調整方法を紹介します。
前回はirisのデータセットを用いてがく長・幅の種間でのばらつきをプロットしましたが、これでは花弁長・幅のデータが加味できていません。そこで今回は主成分分析を用いて4変数を圧縮することを試みます。
主成分分析(PCA)
簡単に説明すると、n次元のデータに対して分散が最も大きくなるような軸を見つけて、それに直交する分散最大の軸を見つけて…ということを繰り返していく作業です。これによって、ばらつきが大きい(=説明能力が高い)順に軸を決め直すことができ、次元を圧縮することができます。
間違ってたらコメントしてください。
さっそくコードを書いてみましょう。といっても1行で終了します。
data.iris <- iris
data.iris.prcomp <- prcomp(data.iris[,1:4])
data.iris.pc <- as.data.frame(data.iris.prcomp$x)
data.iris.pc$Species <- data.iris$Speciesprcomp関数でPCAを実行します。処理後の新たな軸と座標の情報はxというカラムに入ります。PCAは数字で構成されるデータフレームに対してしか実行できないので、一回種名の列を除いてPCAして改めて種名をつけ直すということをしています。
ではプロットしましょう。前回とほぼ同じ
library(ggplot2)
ggplot(data.iris.pc,aes(x=PC1,y=PC2,col=Species))+
theme_classic()+
geom_point()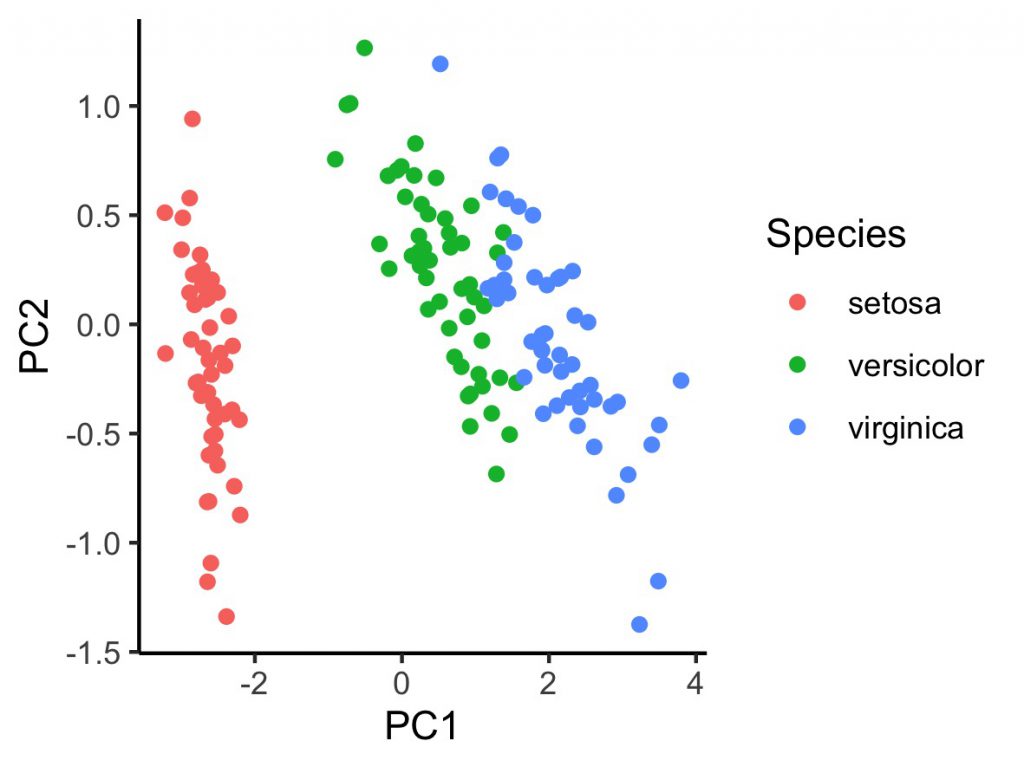
横軸のPC1にそって種がきれいにクラスターを形成していることがわかります。
各PCの寄与率を見てみましょう。prcompで生成されるオブジェクトにsummary関数を適用すると、寄与率がimportanceのカラムに付与されて返ってきます。
data.iris.pcsummary <- summary(data.iris.prcomp)$importance
print(data.iris.pcsummary)
PC1 PC2 PC3 PC4
Standard deviation 2.056269 0.4926162 0.2796596 0.1543862
Proportion of Variance 0.924620 0.0530700 0.0171000 0.0052100
Cumulative Proportion 0.924620 0.9776900 0.9947900 1.0000000
iris.pcsummary.df <- data.frame(contributionOfPCs=data.iris.pcsummary[2,],
PC=colnames(data.iris.pcsummary))
g <- ggplot(iris.pcsummary.df,aes(x=PC,y=contributionOfPCs))+
theme_classic()+
geom_bar(stat="identity",fill="deeppink")
ggsave("fig/1203_2.jpeg",g,width = 10,height = 7.5,units="cm")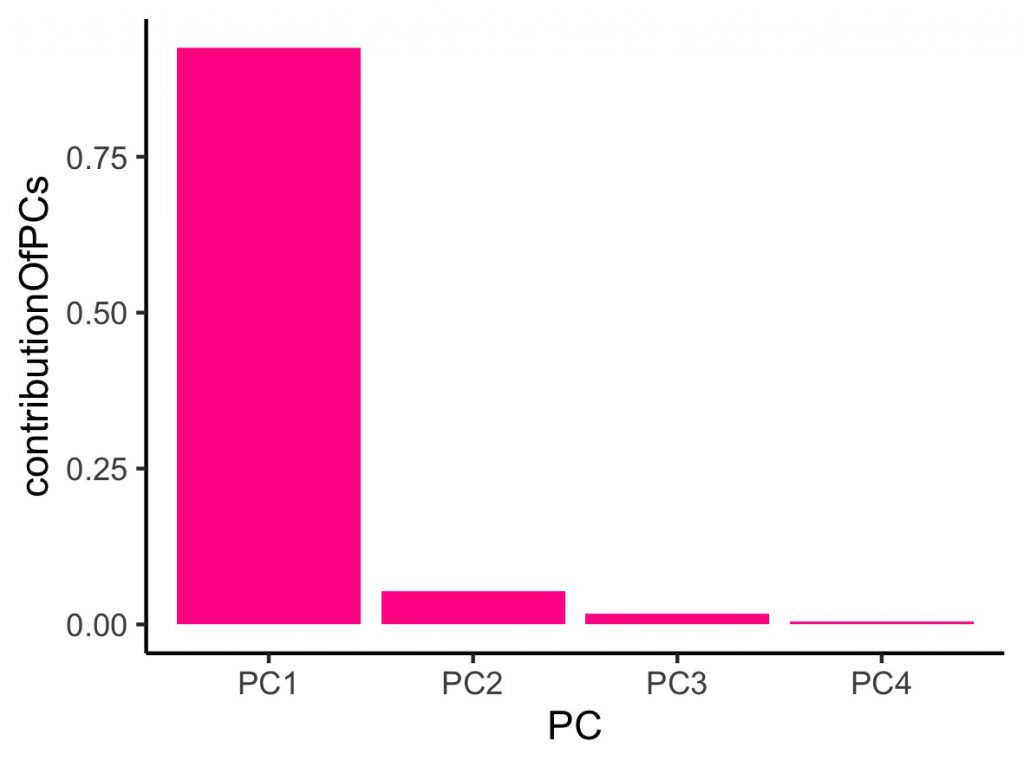
上のように、第一主成分だけでかなりサンプルのばらつきを説明できることがわかりました。散布図を見るとPC1だけでクラスターが分かれていることと一致します。
尺が持つ気がしないので図の調整はまた今度にします。さようなら〜