本日使用する資料のURL: https://x.gd/MSP7P

最初にダウンロードしておいてほしいファイル
全員共通
Windowsユーザー
Macユーザー
2025年 静岡理工科大学 理工学特別講義 (9/11)
本日は、実際のシーケンスデータを用いた解析実習を行います。コンピュータを使い、メタゲノム解析によって環境中の微生物群集の構造を明らかにし、環境DNA解析によって特定の生物種の痕跡を検出するプロセスを、手を動かしながら体験的に学びます。 この講義を通じて、最新のバイオインフォマティクス技術を体験し、生物多様性の保全や生態系の理解といった現代的課題に取り組むための科学的視点と実践的スキルを身につけることを目指します。
実際に行われた実験の紹介(水のサンプリング~DNAシーケンシング)
三四郎池で採水したときの様子(イメージ図)


この池の水から水を汲んでフィルターろ過、DNA抽出を行い、魚もしくはバクテリアDNAを増幅するためのPCRをし、シーケンスを行った。

また、チーズ、ヨーグルト、ハム、塩辛といったバクテリアによる発酵食品からDNAを抽出し、バクテリアDNAを増幅するためのPCR、シーケンスを行った。




PCR結果の紹介
PCR増幅したサンプルの種類
| サンプル | プライマー領域 | 対象生物 | (アダプターの付いた)PCR断片長 |
| 三四郎池の水 | ミトコンドリア12S rRNA | 魚 | 200 bp強 |
| 三四郎池の水 | バクテリア16S rRNA | バクテリア | 1,500 bp程度 |
| 発酵食品 | バクテリア16S rRNA | バクテリア | 1,500 bp程度 |
PCR結果


ポジティブコントロールとして、ギンブナ、ニホンウナギのDNAからMiFishプライマーでPCRを行っている。
リボソームについて

リボソームはRNAとタンパク質の複合体であり、原核生物の場合、大きく50Sと30Sのサブユニットに分かれる。30S複合体の中には16S rRNAが含まれる。

16S rRNA
16S rRNAは保存性の高いConserved Regionsと、変化の多いVariable Regionsが交互に出現する。

rRNAの二次構造ではVariable Regionsを可視化すると下記のようになる。

各Small Sub Unit (SSU)とLarge Sub Unit (LSU)の名前
| Small Sub Unit (SSU) | Large Sub Unit (LSU) | |
| バクテリア | 16S rRNA | 23S rRNA |
| 真核生物 (核) | 18S rRNA | 28S rRNA |
| 真核生物 (ミトコンドリア) | 12S rRNA | 16S rRNA |
| 葉緑体 | 16S rRNA | 23S rRNA |
ミトコンドリアの12S rRNAとバクテリアの16S rRNA
ミトコンドリア12S rRNAは真核生物のミトコンドリアにコードされている遺伝子で、バクテリア16S rRNAに相同な遺伝子である。
12S

16S

使用されたプライマー
| 名前 | 配列 | 生物種 | 増える長さ | 使用したシーケンサー |
| バクテリア16S全長 Forward (27F) | AGAGTTTGATCMTGGCTCAG | バクテリア全般 | 1.5 kbp程度 | Nanopore |
| バクテリア16S全長 Reverse (1492R) | GGTTACCTTGTTACGACTT | バクテリア全般 | 1.5 kbp程度 | Nanopore |
| ミトコンドリア12S MiFish Forward (MiFish-U-F) | GTCGGTAAAACTCGTGCCAGC | 魚類 | 200 bp程度 | Nanopore |
| ミトコンドリア12S MiFish Reverse (MiFish-U-R) | CATAGTGGGGTATCTAATCCCAGTTTG | 魚類 | 200 bp程度 | Nanopore |
解析の概要
本日のデータ解析のワークフローを以下に示します。

データ解析の大雑把な流れとしては、 各サンプルに含まれていた魚、バクテリアの種類を網羅的に解明します。
- シーケンスデータの品質チェック (FastQC)
- シーケンスデータ一つずつがデータベースのどの配列に近いのか相同性検索 (BLAST)
- 相同性検索結果を集計し、各サンプルに含まれていた生物の種類・量を集計 (MEGAN)
配列の相同性検索について
相同性検索について




最も似ているアライメントを効率よく求めるSmith-Watermanアルゴリズム

相同性検索を高速に行うBLASTプログラム
BLASTは、相同性検索(ホモ ロジーサーチ)を比較的高速に行うプログラムである。厳密な解を提供する Smith-Watermanアルゴリズムを少しヒューリスティックにすることで、完全な厳密解は与えないものの実用的には十分な精度を持ちつつ、 Smith-Watermanよりはるかに高速に検索を実現した。 また、BLASTではペアワイズの相同性検索の結果に対して、偶然そのような配列の一致が起こる期待値e-valueを出力し、閾値以上でデータベースとヒットした結果を出力する。
BLASTの高速化の概要
データベース検索する場合、下記のようにデータベース側は100 Gbaseを超える場合もあり、非常に巨大である。しかし、その中で相同な配列というのは通常そんなに多くはない。

そこで、あらかじめwordサイズで指定した大きさで100%マッチする場所を高速に調べておき、その周辺のみ時間をかけて調べることで高速化している。

このwordサイズはNCBIのWEBサイトで公開されているBLAST (https://blast.ncbi.nlm.nih.gov/Blast.cgi )などでは、デフォルトが28 bpと比較的大きめなので、シーケンス精度が悪い場合は注意する必要があるかもしれない。
BLASTプログラムの種類
BLASTでは、問い合わせ配列とデータベース配列の組み合わせから、次の5種類が用意されている。
| プログラム名 | query | db | |
| blastn | DNA | DNA | |
| blastp | protein | protein | |
| blastx | DNA | protein | (DNAはアミノ酸に翻訳して比較) |
| tblastn | protein | DNA | (DNAはアミノ酸に翻訳して比較) |
| tblastx | DNA | DNA | (DNAはアミノ酸に翻訳して比較) |
Blastの結果についての説明
https://www.jaici.or.jp/stn/pdf/seqfaq.pdf

BLASTの出力でE-valueは、指数表記で表されるので注意。例えば、「10-4」は「1.0e-4」と表記される。相同性のあるなしに関しての目安としては、(私は)DNAの場合E-valueが1e-10以下、タンパク質の場合1e-5以下であれば相同性がある(かもと思っている)。BLASTではE-valueが1e-150あたりよりも小さくなると「0」として丸めて表示される。 メタゲノム解析ではE-valueよりも一致率のほうが直感的であり、16S rRNAの場合に一般的には97%以上の一致率で同種であると言われる。ただし、分類群によっては属が違っても一致率100%ということがありうる。
解析手順
A. 準備( ツール・データのダウンロード )
1. ツールのインストール
これからダウンロードするファイルを入れるディレクトリを作成し、その中にすべてのファイルをダウンロードします。とりあえずここではダウンロードフォルダの中に「2025jissyu」というフォルダを作り、そこにこれからダウンロードするファイルを全部移動させたことを前提に書いてあります。(注意:今回使用するプログラムはフォルダ名が日本語になっていると正常動作しません。もしWindowsで「C:\Users\XXX\Downloads\学生実験\2025jissyu」などとパスに日本語が含まれる場合は、「C:\Users\XXX\Downloads\2025jissyu」など途中に日本語フォルダを挟まないフォルダを作ってその中にダウンロードして下さい。OneDriveでダウンロードフォルダを同期させていると「C:\Users\XXX\ダウンロード」と日本語になっていることもあるので注意。)
SeqKit
https://bioinf.shenwei.me/seqkit/download/
Windowsは「Windows amd64」の「seqkit_windows_amd64.exe.tar.gz」、Mac (Intel)は「seqkit_darwin_amd64.tar.gz」、Mac (2020年のM1プロセッサ以降)は「seqkit_darwin_arm64.tar.gz」をダウンロードする。
WindowsではスタートメニューからPowerShellを起動してターミナルを開く。MacではLaunchpad→その他→ターミナルを起動する。
ターミナルに下記のコマンドを入力し、seqkitを解凍する。
#ダウンロードしたディレクトリに移動する。 cd ~/Downloads/2025jissyu/ #ダウンロードしたファイルを解凍する。(Win) tar vxf seqkit_windows_amd64.exe.tar.gz #ダウンロードしたファイルを解凍する。(Mac) tar vxf seqkit_darwin_*.tar.gz
BLAST
https://ftp.ncbi.nlm.nih.gov/blast/executables/blast+/2.16.0/
Windowsは「ncbi-blast-2.16.0+-x64-win64.tar.gz」を、Macは「ncbi-blast-2.16.0+-universal-macosx.tar.gz」をダウンロードし、「2025jissyu」フォルダに移した後で、下記のコマンドを実行する。
#ダウンロードしたファイルを解凍する。 ## Windows tar vxf ncbi-blast-2.16.0+-x64-win64.tar.gz ## Mac tar vxf ncbi-blast-2.16.0+-universal-macosx.tar.gz
FastQC
https://www.bioinformatics.babraham.ac.uk/projects/download.html#fastqc

Windowsは「FastQC v0.12.1 (Win/Linux zip file)」をダウンロードし、上図のように解凍するか、もしくは「2025jissyu」フォルダに移した後で、下記のコマンドを実行する。
Expand-Archive -Path fastqc_v0.12.1.zip -DestinationPath .
Macは「FastQC v0.12.1 (Mac DMG image)」をダウンロードし、ダブルクリックしてイメージをマウントしておく。
Javaランタイム
FastQCを実行するのに必要。https://www.java.com/ja/download/manual.jsp より適切なJavaをインストールする。
Windowsは「jre-8u431-windows-x64.exe」, MacはIntel系のCPUは「jre-8u431-macosx-x64.dmg」を、M1以降のCPUは「jre-8u431-macosx-aarch64.dmg」のインストーラーをダウンロードし、実行してインストールする。

MEGAN
http://software-ab.cs.uni-tuebingen.de/download/megan6/welcome.html
Windowsは「MEGAN6 Community Edition installers」の「MEGAN_Community_windows-x64_6_25_10.exe」をダウンロードし、ダウンロードしたファイルをクリックorダブルクリックしてインストーラーを起動する。
下記の画面が出たら「詳細情報」を開いて

「実行」をクリックする。

インストーラーに従い、「次へ」等を押してインストールを完了する。

Macは「MEGAN_Community_macos_6_25_10.dmg」をダウンロードし、ダウンロードしたファイルをダブルクリックしてディスクイメージをマウントし、インストーラーをダブルクリックして起動する。

開いて良いか聞かれたら「開く」を押す。

インストーラーに従い、「次へ」等を押してインストールを完了する。
2. データベースのダウンロード
- 16S rRNA、18S rRNA、ミトコンドリア、葉緑体等のメタバーコーディングで使用される領域をまとめたFASTAファイルをダウンロードして各自OSの機能でzipファイルを解凍し、中身の
silva-SSU-LSU_PR2_NCBI-16S-mito-plastid_2023-04-18_rename_mitofish-2023-11-07.fastaを「2025jissyu」フォルダにコピーしておく。このファイルは、NCBI blast database (ミトコンドリア、葉緑体)、PR2(18S rRNAなど)、SILVA(16S rRNA, 23S rRNA)、MitoFish (MiFish用12S rRNA)をマージして作ったもの。具体的には下記のファイルをマージしたもの。
https://ftp.ncbi.nlm.nih.gov/blast/db/ から16S_ribosomal_RNA、LSU_prokaryote_rRNA、mitohttp://ftp.ncbi.nih.gov/refseq/release/plastid/ からplastid.*.genomic.fna.gzhttps://github.com/pr2database/pr2database/releases/download/v4.14.0/pr2_version_4.14.0_SSU_taxo_long.fasta.gzhttps://www.arb-silva.de/fileadmin/silva_databases/current/Exports/SILVA_138.1_LSURef_NR99_tax_silva_trunc.fasta.gzhttps://www.arb-silva.de/fileadmin/silva_databases/current/Exports/SILVA_138.1_SSURef_NR99_tax_silva_trunc.fasta.gzhttp://mitofish.aori.u-tokyo.ac.jp/species/detail/download/?filename=download%2F/complete_partial_mitogenomes.zip - Nanoporeのシーケンスデータ ・・・メタゲノムとeDNAのデータが入っています。
zipファイルを解凍し、中身の
XXXX.fqファイルを「2025jissyu」フォルダにコピーしておく。・ eDNA解析: 12SMiFish-XXX.fqのファイルを使用
・ メタゲノム解析(水・食品): 16S-metagenome-X.fq, 16S-food-X.fqのファイルを使用
とりあえずの解析
上記のナノポアシーケンスデータを適当なテキストエディターで開き、塩基配列の部分を一行コピーしておく。

NCBI BLASTのHPを開き、先ほどコピーした塩基配列をテキストボックスに張り付け「BLAST」ボタンを押す。

B. クオリティチェック
FastQCは主にIllumina用のクオリティチェックツールなので、Nanoporeのデータに対しては適切な評価ができておらず、評価値の〇×は気にしなくてよいです。
NGSのクオリティとは
クオリティスコアQから、エラーの生じる確率 P(error) は下記のように計算されます。 (出典: https://bi.biopapyrus.jp/rnaseq/qc/fastq-quality-score.html )

- クオリティスコアが 10 ならば、シーケンシングエラーが生じる確率は 10.0% であるから、読み取られた塩基の信頼度は 90.0% 。
- クオリティスコアが 20 ならば、シーケンシングエラーが生じる確率は 1.0% であるから、読み取られた塩基の信頼度は 99.0% 。
- クオリティスコアが 30 ならば、シーケンシングエラーが生じる確率は 0.1% であるから、読み取られた塩基の信頼度は 99.9% 。
FASTQCを実行するには…
- Windows
解凍したFastQCのフォルダの中の
run_fastqc.batを実行する。 - Mac
dmgファイルを開いて、FASTQCを実行すると、下記のエラーが出ると思う。
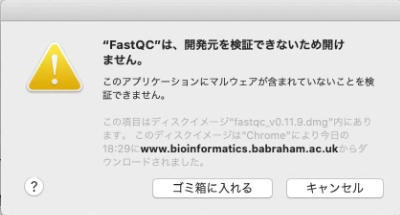
一度「キャンセル」して、「システム環境設定」を開き、 「プライバシーとセキュリティ」を開き、「このまま開く」をクリックしてFastQCを開く。



FastQCでシーケンスファイルを開く

Macでは下記のようにアクセスを許可する必要があるので、許可をする。

Ctrlキーを押しながらクリックすれば、複数のファイルを一度に選択できるので、必要なファイルを選択して開く。(ただし一度に複数選択するとメモリーエラーで落ちたりするので、その場合は一つずつ開くこと。)

結果のタブを開いてみると、次のようなQC結果が見られる。

Nanoporeのデータだとクオリティスコア10強(精度90%強)となるはずですが、リード全体のクオリティは比較的正しく計算できるみたいだけど、塩基ごとのクオリティはあまり正確ではなく、実際の塩基精度とは乖離があるようです。(ナノポアでQ20と出ていても、実際はQ12.5程度。https://labs.epi2me.io/quality-scores/)
リード長の分布が想定される長さになっているかなども確認すること。 (バクテリア16S全長は1.5 kbp程度、魚類ミトコンドリア12S MiFishは200 bp強)
C. BLAST
1. FASTQ→FASTA変換
FASTQファイルをメモ帳などで開いてみると次のように表示されます。

FASTQ形式は 塩基配列とクオリティが両方含まれるファイル形式になりますが、BLASTのプログラムはFASTQ形式では入力ファイルとして受け付けてくれません。BLASTが対応しているのは、塩基配列だけの情報であるFASTA形式になります。
FASTA形式は1つのシーケンスにつき、「>」 で始まる1行のヘッダ行と、2行目以降のACGTのシーケンス文字列で構成されます。

そこで、まずFASTQのクオリティを削除して、FASTA形式に変換します。
./seqkit fq2fa -o 1-metagenome.fasta 1-metagenome.fq
1-metagenome.fq, 1-metagenome.fastaは適当に変更すること。
もしリード数が多い場合は、後のblast検索で時間がかかるので、例えば500リードなどにダウンサンプリングしておく。(特にfood, metagenomeサンプルはリード長が長く、blast検索に時間がかかるのでリード数を減らしておくことを推奨)
#例 ./seqkit sample -n 500 -o 1-metagenome_500.fasta 1-metagenome.fasta
コマンド入力時の便利キー
| カーソルの上・下キー | 前に入力したコマンドを呼び出す。 |
| (Win) Ctrl+Shift+V or 右クリック, (Mac) Cmd+V | 貼り付け |
| tabキー | ファイル名・コマンドの自動補完 |
| Ctrl+C | コマンド強制終了(blastを実行中に止めたい場合など) |
2. BLASTデータベース作成
makeblastdbコマンドによってBLASTのデータベースを作成します。ターミナルで下記のように入力します。
#Blastデータベースを作成 ./ncbi-blast-2.16.0+/bin/makeblastdb -in silva-SSU-LSU_PR2_NCBI-16S-mito-plastid_2023-04-18_rename_mitofish-2023-11-07.fasta -dbtype nucl
-in には入力となるFASTAファイルを指定します。
-dbtype はFASTAファイルがDNA配列であれば「nucl」、アミノ酸配列であれば「prot」を指定します。
3. BLAST検索
FASTA形式に変換したシーケンスデータをクエリーとして、バクテリア16SデータベースもしくはMitoFishデータベースで相同性検索を行います。ターミナルで次のように入力してください。
./ncbi-blast-2.16.0+/bin/blastn -db silva-SSU-LSU_PR2_NCBI-16S-mito-plastid_2023-04-18_rename_mitofish-2023-11-07.fasta -query 1-metagenome_500.fasta -num_threads 16 -out 1-metagenome_500.fasta.blastn
-db には、BLASTデータベースファイルのprefixを指定します。今回の場合は元となったSILVAもしくはMitoFishのFASTAファイルを指定すれば良いです。
-query にはデータベースに対して相同性検索を行いたい問い合わせ配列が含まれるFASTAファイルを指定します。ここではFASTA形式に変換したシーケンスデータを指定します。(ファイル名は適宜変更すること。)
-num_threads には並列計算時に使用するCPUの数を指定します。自分のPCで計算するときは、各自のPCに合わせて設定すること。
-out には出力ファイルの名前を書く。(拡張子はMEGANに読み込ませるために「.blastn」とし、ファイル名は出来れば「入力FASTAファイル名」+「.blastn」としておくとMEGANがFASTAファイルを認識してくれて情報がリッチになる。)
4. BLAST結果例
下記のように入力すると、結果ファイルの中身を先頭30行だけ見ることが出来ます。
## Windows (PowerShell)の場合 Get-Content -head 30 1-metagenome_500.fasta.blastn ## Mac/Linuxの場合 head -n 30 1-metagenome_500.fasta.blastn # 1-metagenome_500.fasta.blastn は適当なファイル名に変更します。


D. MEGANによるBLAST結果集計
1.MEGANではLowest Common Ancestor (LCA)法によってtaxon (分類群)を推測している。LCA法とは、1つのリードがデータベース中の複数の配列にヒットした場合、ヒットした配列に共通の分類群を求める方法です。 http://bio4j.com/blog/2012/02/finding-the-lowest-common-ancestor-of-a-set-of-ncbi-taxonomy-nodes-with-bio4j/ ただ、MEGANのデフォルト値はIlluminaシーケンサー用(精度99.9%)に設定されているので、ナノポアのように80~90%程度の精度では変更する必要があります。

2.インストールしたMEGANを起動します。

3.MEGANが起動したら、「File」→「Import From BLAST」からBLAST結果を開きます。

4.ダイアログ右上のボタンをクリックして、BLASTの結果ファイルを選択し、「Open」をクリックします。(複数ファイルを選択できますが、結果がマージされてしまうので、ファイルを一つだけ選択します。}

5.「LCA Params」タブを開いて、Top Percent: の値を0.5に変更しておきます。このパラメータは、BLASTの結果の中で最もスコアの高いトップヒットからどの程度離れたヒットまで使用するかの閾値になります。ナノポアではシーケンス精度が悪く、無関係な生物も似たようなスコアでヒットしてしまうため、ほぼトップヒットしか使わないように厳しめに閾値を設定しておきます。それから、Min Score: の値をバクテリア16Sではリード長が1500bp程度なので1000、魚類12Sではリード長が200bp程度なので100などと指定し、スコアの低いリードをトリミングします。「Apply」を押すとファイルを読み込みます。

6.結果が表示されたら、 種名まで表示するために、「Rank」→「Species」を選択します。

↓

7.マウスホイールで拡大・縮小できます。もしくはメニューバーの下記のボタンをクリックしても拡大できます。

8.各生物種に割り当てられたBLASTの生データを見たい場合、ノードを右クリックし、「Inspector」を開けば見れます。本当にその生物はいるのか確認したくなった時などに、アライメント長や塩基配列そのものを確認するのに便利です。


9.BLASTファイルを読み込むときに設定したLCAのパラメータを後から変更したい場合は、「Options」→「Change LCA Parameters」から可能です。

10.MEGANで複数サンプルを比較する場合は、blastnファイルを複数回開いたら、開いたウィンドウをそのままにした状態で、「File」→「Compare」とクリックして比較したいサンプルを選択し、「Apply」をクリックします。

11.複数結果の表示を変更する場合、円グラフのボタンなどを押すと良いです。

12.ExcelやR等で解析する場合は、データをタブ区切りテキスト形式でExportする必要があります。Exportしたいノードをクリックして(全部Exportする場合は全部選択(WidnowsならCtrl+a)して)、「File」→「Export」→「CSV Format」をクリックします。

13.Exportするデータを「taxonPath_to_count」に変更します。(ほかのデータ形式でも勿論可)

14.適当な名前を付けて保存します。

E. データの転送、Excelでの解析
ExportしたファイルをExcelで開くには、Excelを起動しておき、ExportしたファイルをExcel上にドラッグアンドドロップすれば良いです。

Excelでデータの概要を把握するのに役立つテクニックとして、条件付き書式を設定することで、データの大小を一目でわかるようにできたりします。

そのほか、「データ」→「フィルター」を使ってみたり、グラフを描いてみたり、Excelの機能で各サンプルでリード数の多い順番に生物種名を並び替えてみるなど。
課題
- 12SMiFishの結果をすべてマージしたExcelファイルを作成し、学務課へ提出すること。
- 12SMiFishの結果から、三四郎池にはどういう魚がいましたか?和名で答えてください。